核心收获: 不要上来就重构,第一次不管了,实现功能就行,第二次也可以不管,第三次再去考虑重构 refactor和feature要分开上库 重构架构设计不要想太远了
重构是什么以及为什么?
- 重构是在不改变软件可观测行为的前提下,调整代码结构,以提高软件的可理解性、降低变更成本。
- 重构是一种经济行为,而非道德行为。如果它不能让我们更快、更好地开发,那就没有意义。
- 代码的写法应该使别人理解它所需的时间最小化,进而使变更代码所需的时间也最小化。
- 重构对个体程序员的意义是提高 ROI。
- 更快定位问题,节省调试时间。
- 最小化变更风险,提高代码质量,减少修复事故的时间。
- 获得程序员同行的认可,带来更好的发展机会。
- 重构对整个研发团队的意义是提升战斗力。
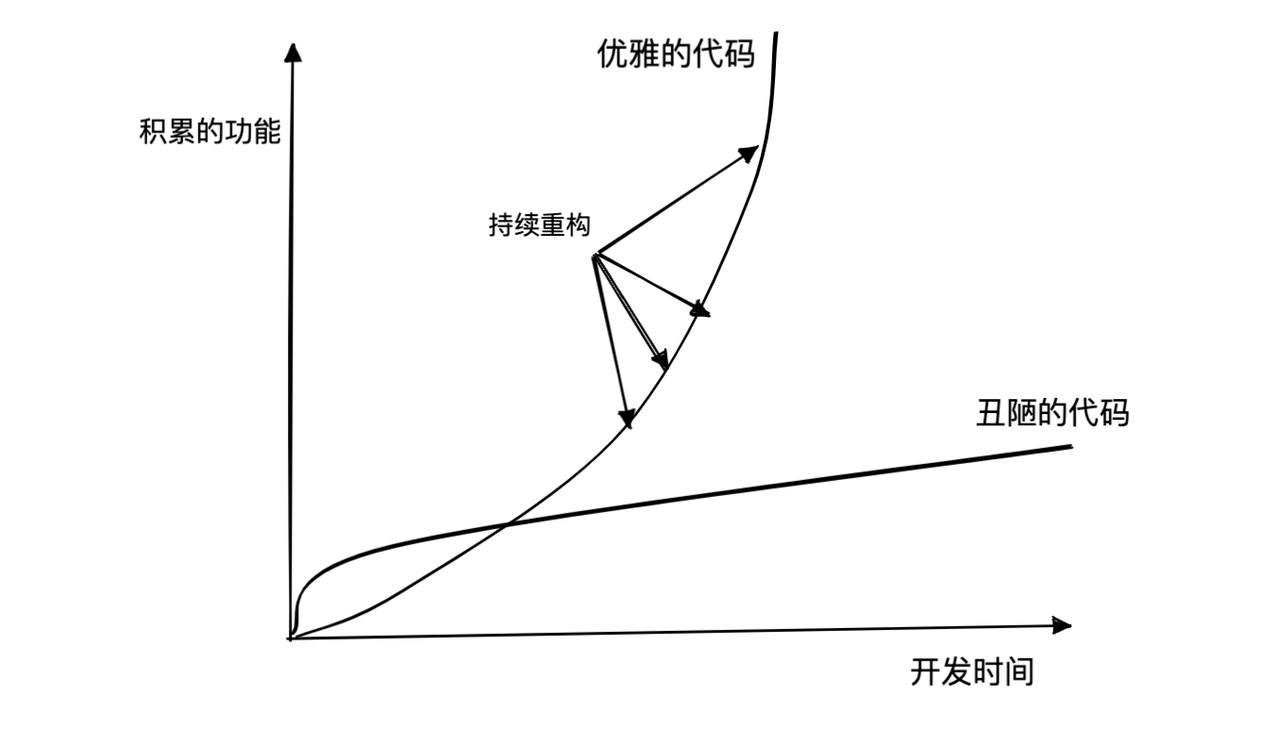
重构的原则
- 重构的目标:提高迭代效率。
- 获得同行认可的方法:每一次提交代码,都应该使代码变得更好,先重构,再开发。
- 增量式重构 = 自动化测试 + 持续集成 + TDD 驱动重构。
代码 / 架构的坏味道
所谓优雅的代码,就是易于理解、可扩展性良好。
以下是 UP 主的 6 类分类,源于上述 24 种坏味道。
依赖传递
交互产生依赖,多模块之间的影响被交叉放大。
变更放大(涉及的子类太多了,需要全部测试和重新上线)
修改点被交叉放大,一次迭代需要修改 N 个位置。每一处修改点都可能带来调试、编译、构建、测试、上线等环节,致使效率低下,操作变得复杂,容易遗漏或失误。
func packVideo(longVideo, sortVideo) *videoInfo {
...
// logic
...
}关注放大(虽然只需要看 2 行代码,可能需要看上下文几百行代码)
关注点被交叉放大。为了完成一次迭代任务,需要通读修改点附近上下文的代码;而由于依赖被继续传递,附近的代码又会牵扯出更多需要关注的代码。通常,为了弄清楚修改点的影响范围,需要理解超出此次迭代任务 10 倍以上的代码量。需要关注的上下文过多,会造成心智负担,也会让测试、调试、上线极易出错。
最终,演变成未知的未知(变更后不知道是否会出问题的状态)。
// query: 1231232|23423|sdfs|342|dsfsdf|sdfsdfd
func ParseData(dataArray []string) string {
....
if len(dataArray) >= 10 {
arrLen := len(dataArray)
deviceID, _ := strconv.ParseInt(dataArray[5], 10, 64)
userID, _ := strconv.ParseInt(dataArray[arrLen-6], 10, 64)
itemID, _ := strconv.ParseInt(dataArray[arrLen-5], 10, 64)
xxxID, _ := strconv.ParseInt(dataArray[arrLen-4], 10, 64)
xxxID := dataArray[arrLen-3]
from := dataArray[arrLen-2]
if len(dataArray) >= 18 {
a, _ := strconv.ParseInt(dataArray[arrLen-7], 10, 64)
b = groupIdTmp
c, _ := strconv.ParseInt(dataArray[arrLen-6], 10, 64)
from = dataArray[arrLen-3]
}
}
....
}神秘命名
代码和注释本质上都是符号的集合。如果这些符号不能被人快速理解,或者因为信息冗余、无效而增加了阅读负担,就会降低可理解性。
好的命名应该有三种境界:信、达、雅。
- 信:准确无误地表达清楚行为的意义,做到见名知意。
- 达:考虑命名对整体架构的影响,与架构的设计哲学风格统一。
- 雅:生动形象,看到名字即可准确理解其在整个程序中的作用,并能产生辅助理解的形象。
Bad case:https://github.com/dgraph-io/dgraph
过度设计(没必要想太长久,只需要考虑一年;或者遇到同样的问题三次,再去设计。中庸之道。)
当过分考虑程序未来所要面对的需求时,就会陷入过度设计的陷阱。为了未来用不上的能力,而使当下的程序变得复杂。
设计变得复杂,是因为考虑了过多的设计约束,而这些约束很可能是现在和未来都不需要的。错把这些约束条件当作目的,就会使目标被放大,最终设计出没有解决实际问题的系统。
过分放大未来的某些风险,而这些风险发生的概率又过低,在项目可见的生命周期内都不太可能遇到,因此也没必要为此进行设计。
Bad case:对于一个 50w DAU 的 IM 系统,考虑过多的未来因素。
结构泥团
对于核心的数据结构,如果没有规范化的设计,就会导致混乱。
艰难引用
未充分考虑数据结构的读取场景,导致在需要使用某些数据时无法简单地获得其引用;或者为了使用某个字段,需要了解一堆中间封装的数据结构。
a.b.c.d.e()全局盲区
大型项目开发中,由于大家缺乏全局视角,对数据结构或者接口的设计不可避免地会造成冗余或混乱。接口与结构的设计充满局部最优解,但从项目整体上看却成为一团泥球。
什么时候需要重构?
- Code review:在给别人做 code review 时嗅出坏味道,并在不失礼貌的前提下提出建议。
- 每次 commit 代码时:每一次经你之手提交的代码,都应该比之前更加干净。
- 当你接手一个异常难读的项目时:说服项目组将重构作为一项需求任务来做。
- 当迭代效率低于预期时:将重构当作一个专项任务来做,必要的时候停下来迭代需求。
重构的手段
一种自底向上的演进方法
| 名称 | 目的 | 场景 | 做法 |
|---|---|---|---|
| 提炼变量 | 让表达式更加可读 | 当存在难以阅读的表达式时(逻辑 / 计算) | 1. 划分子表达式 2. 使用有意义的名称命名子表达式 |
| 提炼函数 | 将意图与实现分离 | 1. 有大量重复的逻辑段时 2. 如果需要浏览一段代码才能理解其在做什么时 | 1. 识别变量依赖 2. 给函数命名 3. 确定函数体的存放位置 4. 构造参数,在目标位置进行调用 5. 编译、测试 |
| 封装类型 | 高内聚,低耦合 | 1. 大量重复的相同 / 相似变量被同时传递 2. 存在大量参数与逻辑无需关心 | 1. 从函数的变量和行为上发现相关性 2. 从高度相关的函数中抽象出一个概念 3. 将概念具象化为一种类型 / 对象 4. 为其设计合理的名称以及生命周期 |
| 模块化 | 逻辑划分,代码复用 | 当一些类需要频繁配合完成一个独立功能时 | 1. 关注点分离,抽象出模块 / 类库 2. 模块内部类相互紧密协作 3. 模块外部通过接口相互调用 4. 模块之间保持单一方向依赖 |
| 封装阶段 pipeline | 保持单一原则 | 1. 一段函数中同时处理多种事情时 2. 多个 if / else 代码杂糅在一起时 3. 逻辑分支膨胀或循环冗余时 | 1. 抽象出多个任务阶段,并对阶段命名 2. 将阶段和处理的参数对象进行分离 3. 利用接口 / 多态特性替换 if / else 模式 |
| 委托模式 | 分离变化与不变的逻辑 | 被调用方会频繁变更时 | 封装接口,通过依赖倒置隔离下游变更 |
| 服务化 / 多进程 | 资源隔离(机器 / 人力) | 1. 当某一个接口需要大量状态与资源时 2. 为了提高运行时稳定性时 | 1. 注册一个新的 Git 仓库 2. 迁移代码,搭建 CI/CD 流程 |
| 配置化 | 提高研发效率,减少重复需求 | 1. 当存在大量反复出现的重复需求时 2. 业务需求频繁,团队疲于应付时 | 抽象通用业务模型 |
| 领域化 | 微服务划分,拆分核心领域 | 当具有一组完整业务交付价值的功能需要复用时 | 1. 提供完整的架构方案 2. 设计对外接口,提供 SDK 3. 完善接入流程 |
| 中台化 | 研发效能复用 | 当公司多个业务具有相同功能时 | 1. 在系统化的基础上进行多租户化 2. 做好权限 / 资源管理 |
| 平台化 | 自动化业务流程 | 1. 当业务需求模式清晰,需要边界明确时 2. 当研发成本成为最大成本时 3. 当要规模化获客接入时 | 1. 抽象自动化流程 pipeline 2. 将研发介入的流程配置化 3. 将配置通过平台调度自动化 4. 做好权限 / 资源 / 计量 / 计费 / 数分 |
| 产品 / 开源化 | 1. 向公司外部提供产品服务 2. 榨取研发资源的剩余价值 3. 产品复杂度过高,超出内部研发能力 | 1. 技术资源不能创造更大价值时 2. 市场需求明确,规模化获客与续约不成问题时 3. 用户增长逻辑明确时 | 1. 提供对外 Open API 2. 提供产品化的角色 / 权限 / 资源管理能力 3. 恰到好处地处理客户 / 用户使用问题 |
重构的基本步骤
代码分析
通读代码,分析现状,找到代码在各个层面的坏味道。
重构计划
重构应该永远是一种经济驱动的决定。
对坏味道进行宣讲,并向团队给出重构的理由,以及重构的计划。
确定重构的目标,明确的描述出重构后能达到的预期是什么。
重构计划中必须给出测试验证方案,保证重构前与重构后软件的行为一致。
如果没有这样的方案,那就必须先让软件具有可测试性。
如果无法得到团队的认可,那就偷偷进行,因为重构始终是对自己有利的(减少工作量以及获得同事的认可)
将重构任务当作项目来管理,对指定任务的人明确的排期和进度同步。
小步子策略
将重构任务拆分成每周都能见到一点效果的小任务。
每一步重构都要具有收益,并且可测试,不能阻断当前需求的迭代。
重构任务必须被跟踪,要定期的开会同步进度,来不断加强团队的重构意识。
测试驱动
对于小型软件,需要先补充单元测试再进行重构。
对于大型软件,先搭建自动化测试流程,再进行重构。
对于复杂的不确定性业务,也可以使用ab test来验证重构对指标的影响,避免造成效果/广告的损失。
要保证测试的完备性与可复用性,尽可能的做到团队级的复用。
保证测试环境与生产环境的一致性也是测试驱动的重要环节。
提交规范
每次提交尽量控制在2分钟可以给code review的同事讲明白的程度
重构应该被当作一次专门的commit中完成,在commit中写清楚改动点&测试点
提交规范有助于定位bug,也是代码可读性的一个重要环节
自动化测试
构建可测试的软件,首先要构建可测试的环境。
对于简单应用软件可以使用单元测试,mock数据进行测试,并与ci/cd流程集成。
对于复杂应用软件可以采样收集线上真实用户行为日志,mock数据周期性巡检测试。
对于幂等性业务,可以mock user进行全方位的端到端自动化巡检测试。
每一次功能的提交应该对应一套完整的自动化测试的策略脚本以及&监控指标与报警规则
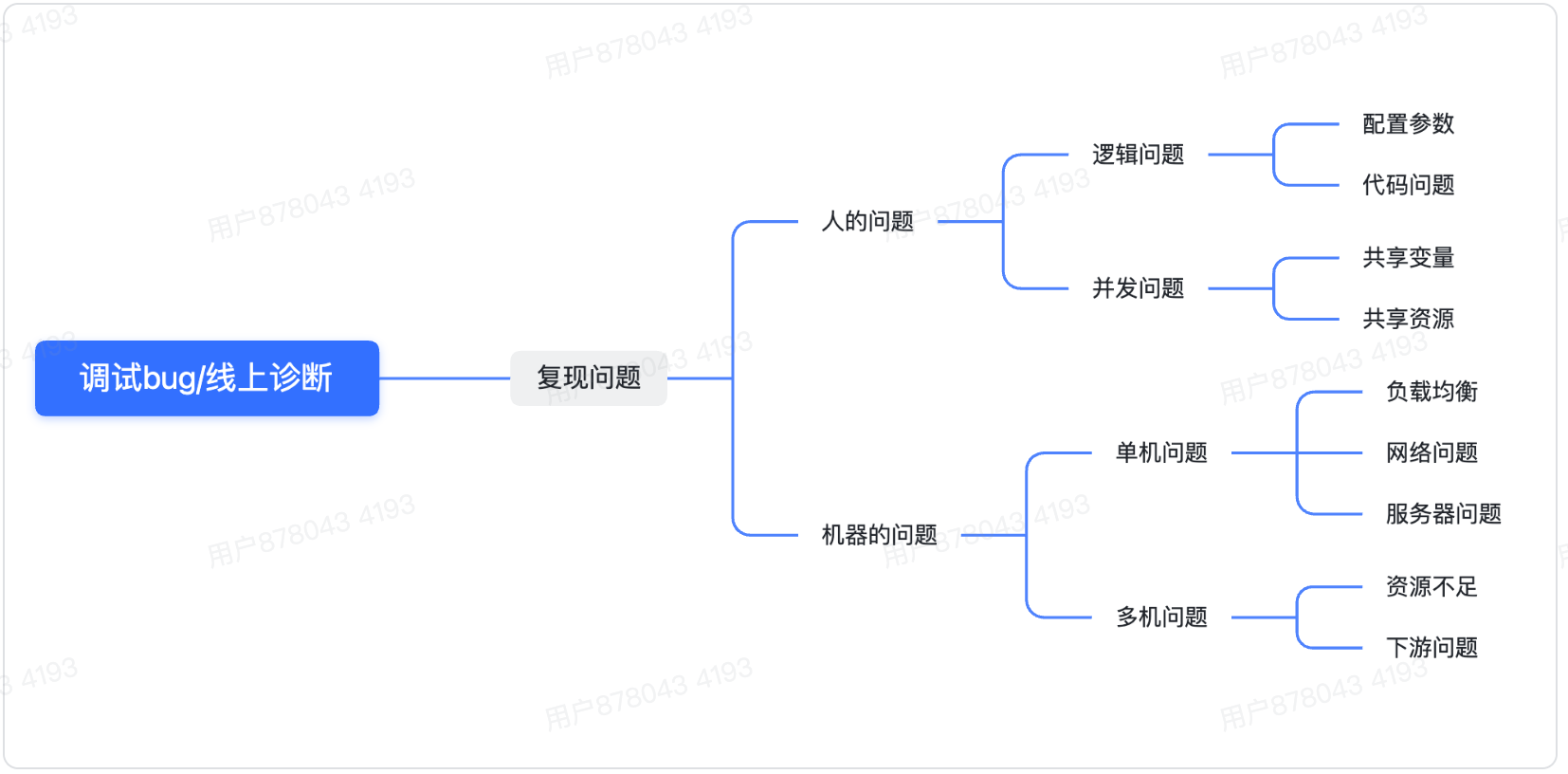
调试BUG
- 亲自复现问题,关注第一现场,确定是必现还是偶现?
- 区分是人的问题还是环境的问题?
- 如果是人的问题,那是配置参数的问题还是代码逻辑的问题?
- 如果是配置参数的问题,则通过对比正常运行的配置参数发现问题
- 如果是代码逻辑的问题,则通过cimmit的历史二分查找缩小出现问题的逻辑范围
- 如果是机器的问题,确定是单机问题还是集群问题。
- 如果是单机问题,则替换机器,如果是集群问题则考虑升级硬件设备。
高质量上线
每次一次上线都必须具有上线计划,发布上线单可追溯可排查问题,关注上线前和上线后指标变化。
上线单写明: 改动点,风险点,止损方案,变更代码,相关负责上下游人员。
一些实际的问题
代码所有权
代码仓库的所有权会阻碍重构,调用方难以重构被调用方的代码(接口),进而导致自身重构的受阻,使得效率降低,为提高开发的效能,允许代码仓库在内部开源化,其他团队的工程师可以通过pr自己来实现代码,并提交给仓库的onwer,来code review即可。
没有时间重构
这是重构所面临最多的借口,是自己也是团队的借口。 为此必须要明确重构是经济行为而不是一种道德行为,重构使得开发效率变得更高,因此仅对必要的代码进行重构,某个工作行为如果重复三次就可以认为未来也会存在重复,因此通过重构使得下次工作更加高效,这是一种务实的作法,而重构不一定是需要大规模的展开的任务,重构应该是不断持续进行的,将任务拆解为多个具有完备性的任务,每周完成一个,每个任务的上线都不会引起问题,并使项目变得更好,这是一种持续重构的精神态度,是高效能程序员最应该具有的工作习惯。
如果你在给项目添加新的特性,发现当前的代码不能高效的完成这个任务,并且同样的任务出现三次以上,那么这时你应该先重构,再开发新特性。
重构导致bug
历史遗留的代码实在太多,难以阅读理解,如果无法理解谁也不敢轻易重构,害怕招致bug引起线上事故,因此在重构之前必须有一套相对完备的测试流程,他能给予程序员信心,也是重构的开始,反过来想对于谁也不愿意重构的代码进行重构,将收益巨大(这个项目还会继续迭代时)