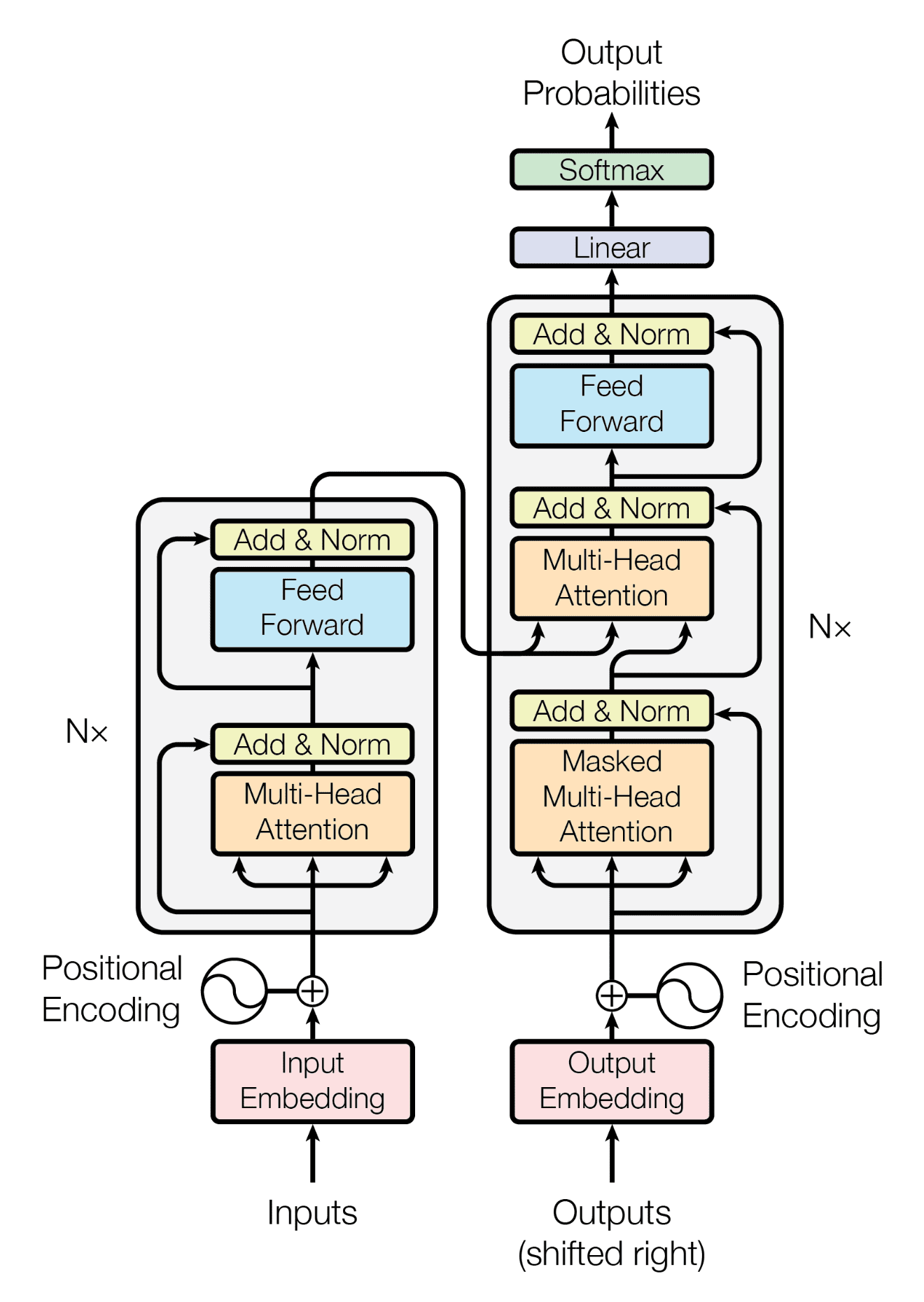
Input(pos)=Embedding(tokenpos)+PositionalEncoding(pos)
第 pos 个 token 的输入 = 第 pos 个 token 的词向量 + 第 pos 个位置的位置编码向量
PositionalEncoding是个什么计算:
PE(pos)=sin(0)sin(1)sin(2)sin(3)cos(0)cos(1)cos(2)cos(3)sin(0)sin(0.01)sin(0.02)sin(0.03)cos(0)cos(0.01)cos(0.02)cos(0.03)
PE(pos,2i)=sin(10000dmodel2ipos)PE(pos,2i+1)=cos(10000dmodel2ipos)
- pos:单词在序列中的位置
- dmodel:词向量的维度(固定值)
- i:位置编码向量中的维度索引,范围在 [0,2dmodel−1]
位置编码向量的维度是成对设计的:偶数维用 sin,奇数维用 cos。所以 i 只需要遍历前一半的索引,就能生成长度为 dmodel 的完整位置编码向量。
推导过程
目的是寻找到式子满足:pos+k的位置编码可以由于pos的位置线性表示就行
PE(pos+k)=T×PE(pos)
从论文已知
α=10000dmodel2ipos,β=10000dmodel2ik
则
PE(pos+k,2i)=sin(α+β)=sin(α)cos(β)+cos(α)sin(β)=PE(pos,2i)cos(β)+PE(pos,2i+1)sin(β)
PE(pos+k,2i+1)=cos(α+β)=cos(α)cos(β)−sin(α)sin(β)=PE(pos,2i+1)cos(β)−PE(pos,2i)sin(β)
可以合并为矩阵写法
T×PE(pos)=PE(pos+k)
[cos(β)−sin(β)sin(β)cos(β)][PE(pos,2i)PE(pos,2i+1)]=[PE(pos,2i)cos(β)+PE(pos,2i+1)sin(β)PE(pos,2i+1)cos(β)−PE(pos,2i)sin(β)]=[PE(pos+k,2i)PE(pos+k,2i+1)]
从数学上看,在固定 k 的情况下,较小的 i 对应更高频的变化,位置编码随位置变化更快,因此更侧重刻画局部位置信息;较大的 i 对应更低频的变化,位置编码变化更平缓,因此更适合表达全局位置信息
举个例子
序列长度为 4,词向量维度为 4。
PE(pos,2i)=sin(10000dmodel2ipos)PE(pos,2i+1)=cos(10000dmodel2ipos)
这里 dmodel=4,所以 i=0,1。
于是:
- 第 0 维:sin(pos/100000)=sin(pos)
- 第 1 维:cos(pos/100000)=cos(pos)
- 第 2 维:sin(pos/100002/4)=sin(pos/100)
- 第 3 维:cos(pos/100002/4)=cos(pos/100)
所以 4 个位置 pos=0,1,2,3 的位置编码矩阵为:
PE=sin(0)sin(1)sin(2)sin(3)cos(0)cos(1)cos(2)cos(3)sin(0)sin(0.01)sin(0.02)sin(0.03)cos(0)cos(0.01)cos(0.02)cos(0.03)
近似数值是:
PE≈00.84150.90930.141110.5403−0.4161−0.990000.01000.02000.030010.999950.999800.99955
ROPE位置编码
Transformer原生词向量算法的问题:位置权重直接累加在词向量上,污染了语义,分不清是哪一部分
Q=Wq(Xm+Pm),K=Wk(Xn+Pn)
Score=(Xm+Pm)(Xn+Pn)⊤=(Xm+Pm)(Xn⊤+Pn⊤)=XmXn⊤+XmPn⊤+PmXn⊤+PmPn⊤
结果 = 纯语义*纯语义+噪声1+噪声2+纯相对位置
核心思想:位置权重加法改为了旋转
Q=RmXm,K=RnXn
Score=(RmXm)(RnXn)⊤=Xm(Rn−Rm)Xn⊤
很纯净
推导过程
已知逆时针旋转矩阵
R(α)=[cosαsinα−sinαcosα]
且如果是第 m 个词,就逆时针旋转 mθ 个角度;第 n 个词,就逆时针旋转 nθ 个角度。
假设原始向量是 q 和 k,旋转后的向量分别是 q′ 和 k′。
q′=R(mθ)q
k′=R(nθ)k
已知注意力公式,点积注意力分数(未缩放)
score(q,k)=q⋅k=i=1∑dkqiki
缩放后的注意力分数
score(q,k)=dkq⋅k
Softmax 归一化之后的注意力权重矩阵
A=softmax(dkQK⊤)
Scaled Dot-Product Attention 输出
Attention(Q,K,V)=softmax(dkQK⊤)V
则有
Score=(q′)⊤⋅k′=(R(mθ)⋅q)⊤⋅(R(nθ)⋅k)=q⊤⋅R(mθ)⊤⋅R(nθ)⋅k
假设
α=mθ,β=nθ
且
R(α)⊤=(cosαsinα−sinαcosα)⊤=(cosα−sinαsinαcosα)=(cos(−α)sin(−α)−sin(−α)cos(−α))=R(−α)=R(−mθ)
并且
R(−mθ)⋅R(nθ)=(cosα−sinαsinαcosα)(cosβsinβ−sinβcosβ)=(cos((n−m)θ)sin((n−m)θ)−sin((n−m)θ)cos((n−m)θ))=R((n−m)θ)
最终
Score=(q′)⊤⋅k′=q⊤⋅R(mθ)⊤⋅R(nθ)⋅k=q⊤⋅R(−mθ)⋅R(nθ)⋅k=q⊤⋅R((n−m)θ)⋅k
θi=10000−dmodel2(i−1),i∈[1,2,…,2dmodel]
这样一个对焦块的形式
cosαsinα00⋮00−sinαcosα00⋮0000cosαsinα⋮0000−sinαcosα⋮00⋯⋯⋯⋯⋱⋯⋯0000⋮cosαsinα−sinαcosα0.90.21⋮−0.30.23
举个例子
X=100.5010.50.50.10.20.20.30.1
R(θ1)=(cosθ1sinθ1−sinθ1cosθ1)≈(0.54030.8415−0.84150.5403)
R(θ2)=(cosθ2sinθ2−sinθ2cosθ2)≈(0.999950.0099998−0.00999980.99995)
RRoPE=(R(θ1)00R(θ2))=0.54030.841500−0.84150.540300000.999950.009999800−0.00999980.99995
XRoPE≈0.54030.84150.6909−0.84150.5403−0.15060.5019750.1030450.198990.194990.3009850.101995